





【Python】ヤフオクの自動延長なし商品を抽出してみた!
当ページのリンクには広告が含まれています。

この記事で解決できる悩み
 いずみ
いずみこんな悩みを解決できる記事を書きました!
僕は現役フリーランスエンジニア(歴10年)で、資格は13個保有しています。
「ヤフオクの自動延長なし商品を抽出する方法が知りたい」とお考えではありませんか?
ということで、ヤフオクの自動延長なし商品を抽出するツールを開発しました。
いずみなるべくコードは分かりやすく書いたので参考にしてみてください。
ということで、本記事ではヤフオクの自動延長なし商品を抽出する方法を解説します。
 いずみ
いずみすぐ読み終わるので、ぜひ最後まで読んでくださいませ。
スクロールできます
| 【当サイト】おすすめフリーランスエージェント3選 | |||
|---|---|---|---|
| エージェント | 評価 | ポイント | 公式サイト |
レバテックフリーランス | 5.0 | 業界最大級のエージェント。 高単価案件が豊富。 | 公式 |
Midworks | 4.8 | 満足度調査で 3年連続3冠を達成。 | 公式 |
ITプロパートナーズ | 4.6 | 週2〜3向けの案件が豊富。 | 公式 |
よく読まれている記事はこちら!
目次
ヤフオクの自動延長なし商品とは?
ヤフオクは基本的にオークション形式なので、落札時間直前に入札が入ると自動で時間が延長されます。
時間が延長されれば価格が競り上がるので出品者としてはありがたいわけですが、たまに自動延長の設定を忘れているユーザがいます(つまり、商品の価格が競り上がらず時間が来たら終了する)。
こういった商品を狙うことで安く商品を仕入れられます。
ツールを作った理由
自動延長なしの商品かどうかは、各商品の詳細ページを見ないと分かりません。
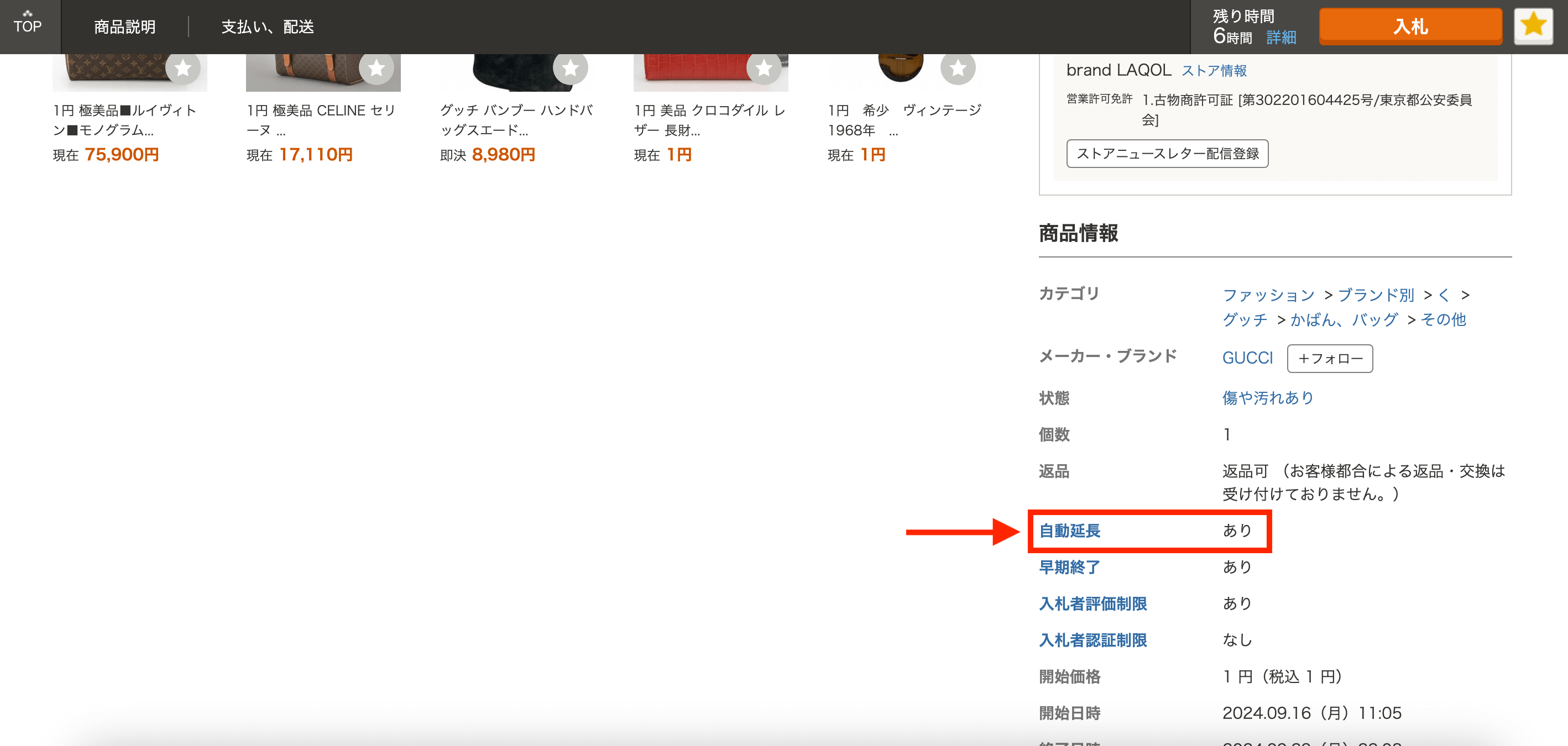
↑のように、各商品の詳細ページに自動延長「あり」「なし」の記載があります。
自動延長の確認を手動でやるのは超非効率なのでツールを作りました。
ツールについて
ツールのソースコードを載せておきます。
ソースコード
import csv
import logging
import os
import random
import time
import tkinter as tk
from functools import wraps
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
options = Options()
# options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(10)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
datefmt="%Y/%m/%d %H:%M:%S"
)
logger = logging.getLogger(__name__)
def sleep():
time.sleep(random.uniform(2, 5))
def sleep_after_execution():
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
sleep()
return result
return wrapper
return decorator
def delete_csv_file():
if(os.path.isfile("disappointing.csv")):
os.remove("disappointing.csv")
if(os.path.isfile("automatic_extension.csv")):
os.remove("automatic_extension.csv")
@sleep_after_execution()
def open_site():
driver.get("https://auctions.yahoo.co.jp/")
@sleep_after_execution()
def delete_ad():
try:
driver.find_element(By.CSS_SELECTOR, "div > a.Close-sc-uncojt.UslsY").click()
except:
pass
@sleep_after_execution()
def search(keyword):
driver.find_element(By.CSS_SELECTOR, "div > input").send_keys(keyword)
driver.find_element(By.ID, "acHdSchBtn").click()
@sleep_after_execution()
def filter_price(min, max):
if min is not None:
driver.find_element(By.XPATH, "//input[@name='min']").send_keys(min)
if max is not None:
driver.find_element(By.XPATH, "//input[@name='max']").send_keys(max)
driver.find_element(By.CSS_SELECTOR, "form > input.Button.u-marginT10").click()
@sleep_after_execution()
def select_auction_mode():
driver.find_element(By.CSS_SELECTOR, "div.Tab > ul > li:nth-child(2) > a").click()
@sleep_after_execution()
def sort():
driver.find_element(By.CSS_SELECTOR, "li:nth-child(1) > div > button").click()
driver.find_element(By.CSS_SELECTOR, "li:nth-child(1) > ul > li:nth-child(2) > a").click()
@sleep_after_execution()
def select_item_number():
driver.find_element(By.CSS_SELECTOR, "li:nth-child(2) > div > button").click()
driver.find_element(By.CSS_SELECTOR, "li:nth-child(2) > div > ul > li:nth-child(2) > a").click()
def get_hrefs_per_page():
hrefs = []
hrefs_elem = driver.find_elements(By.CSS_SELECTOR, "div.Product__detail > h3 > a")
for elem in hrefs_elem:
href = elem.get_attribute("href")
hrefs.append(href)
return hrefs
def get_hrefs():
hrefs = []
while True:
try:
hrefs.extend(get_hrefs_per_page())
driver.find_element(By.CSS_SELECTOR, "li.Pager__list.Pager__list--next > a").click()
sleep()
except:
break
return hrefs
def write_csv(file_name, href):
with open(file_name, mode="a", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([href])
def create_csv_file(hrefs):
for href in hrefs:
driver.get(href)
try:
remaining_time_unit = driver.find_element(By.CSS_SELECTOR, "span.Count__detail > span").text
except:
continue
if remaining_time_unit == "日":
break
title = driver.find_element(By.CSS_SELECTOR, "h1").text
if len(title) < 30:
write_csv("disappointing.csv", href)
automatic_extension = driver.find_element(By.CSS_SELECTOR, "tr:nth-child(5) > td").text
if automatic_extension == "なし":
write_csv("automatic_extension.csv", href)
sleep()
def open_url(file_name):
with open(file_name, newline='') as csv_file:
urls = csv.reader(csv_file)
for url in urls:
driver.execute_script("window.open('');")
driver.switch_to.window(driver.window_handles[-1])
driver.get(url[0])
def main(keywords, min_price, max_price):
try:
logger.info("処理開始")
delete_csv_file()
open_site()
delete_ad()
for keyword in keywords:
logger.info(f"キーワード「{keyword}」を処理中...")
search(keyword)
filter_price(min_price, max_price)
select_auction_mode()
sort()
select_item_number()
hrefs = get_hrefs()
create_csv_file(hrefs)
open_url("disappointing.csv")
open_url("automatic_extension.csv")
logger.info("処理終了")
except Exception as e:
logger.error(f"予期せぬエラーが発生しました: {e}")
if __name__ == "__main__":
root = tk.Tk()
root.geometry(f"{root.winfo_screenwidth()}x{root.winfo_screenheight()}")
root.title("自動延長なし商品抽出ツール")
tk.Label(root, text="検索ワード").grid(row=0, column=0, padx=10, pady=5)
keyword_input = tk.Text(root)
keyword_input.grid(row=0, column=1, padx=10, pady=5)
tk.Label(root, text="最小金額").grid(row=1, column=0, padx=10, pady=5)
min_price_input = tk.Entry(root)
min_price_input.grid(row=1, column=1, padx=10, pady=5)
tk.Label(root, text="最大金額").grid(row=2, column=0, padx=10, pady=5)
max_price_input = tk.Entry(root)
max_price_input.grid(row=2, column=1, padx=10, pady=5)
button = tk.Button(root, text="実行", command=lambda: main(keyword_input.get("1.0", tk.END).strip().split("\n"), min_price_input.get(), max_price_input.get()))
button.grid(row=3, columnspan=2, pady=10)
root.mainloop()実行方法
$ python3 yahoo_auction.py pythonコマンドを実行すればOKです。
ツール解説
ざっくり以下のような感じです
- GUIで「検索ワード」「最小金額」「最大金額」の入力ができる。
- 入力した検索条件を元に、当日の商品情報を抽出する。
- 自動延長なし商品の情報は「automatic_extension.csv」に出力される。
- おまけ機能として、タイトルが短い(30文字以下)商品も抽出。「disappointing.csv」に出力される。
いずみあとは適当に改良してみてください。
スクロールできます
| 【当サイト】おすすめフリーランスエージェント3選 | |||
|---|---|---|---|
| エージェント | 評価 | ポイント | 公式サイト |
レバテックフリーランス | 5.0 | 業界最大級のエージェント。 高単価案件が豊富。 | 公式 |
Midworks | 4.8 | 満足度調査で 3年連続3冠を達成。 | 公式 |
ITプロパートナーズ | 4.6 | 週2〜3向けの案件が豊富。 | 公式 |
【厳選】フリーランスエンジニアにおすすめなエージェント3選

フリーランスエンジニアになるにはエージェントから案件をもらう必要があります。
僕が実際に利用しているおすすめエージェントを紹介しますね。
いずみエージェントは必ず複数登録してください。
担当者によっては「全然案件紹介してくれない…」みたいなこともあるので…
僕は実際に5つのエージェントを使い回していますよ。
フリーランスを始めるなら「レバテックフリーランス
 」
」
| 案件数 | マージン率 | 単価 | |
| 約88,000件 | 非公開 | 高 | |
| 初心者 | 福利厚生 | 申し込み | |
| 無料 |
Good Point
- 業界最大級の案件数。
- 業界トップクラスの高単価報酬、低マージン(平均年収862万円)。
- 案件参画中のフォローの充実。
※詳細は「【業界最大手】レバテックフリーランスとは?メリットや利用手順を解説!」を参照。
レバテックフリーランス
![]() は業界最大手のフリーランスエージェントです。
は業界最大手のフリーランスエージェントです。
とにかく案件数が多いので、とりあえず登録しておけば間違いないエージェントです!
いずみ僕もはじめてフリーランスの案件を貰ったのはレバテックフリーランス
![]() です。
です。
保有している案件数が多いので、業務経験がなくても何かしらの案件は紹介してもらえますよ(僕はJavaの経験3年でも案件を貰えました)。
手厚い保障を重視したいなら「Midworks
」
| 案件数 | マージン率 | 単価 | |
| 約10,000件 | 非公開 | 中 | |
| 初心者 | 福利厚生 | 申し込み | |
| 無料 |
Good Point
- 手厚い保障で正社員並みの安心感。
- 還元率60%超え&単価公開でクリアな契約。
- 給与保障制度(審査あり)。
Midworks
![]() は手厚い保障が特徴のフリーランスエージェントです。
は手厚い保障が特徴のフリーランスエージェントです。
フリーランスを目指しているけど不安な方や保障を重視したい方におすすめです。
いずみ僕も何度か案件を紹介してもらいました。
自分のスキルに合った案件を紹介してもらえましたし、電話のやり取りも非常に丁寧でした。
週2〜3日の案件探しなら「ITプロパートナーズ
」
| 案件数 | マージン率 | 単価 | |
| 約5,000件 | 非公開 | 高 | |
| 初心者 | 福利厚生 | 申し込み | |
| 経験者向け | 無料 |
Good Point
- IT案件に特化したフリーランスエージェント。
- 週2〜3日の案件が豊富。
- リモート案件が多く、直エンドなので単価も高い。
※詳細は「【週2・3案件】ITプロパートナーズとは?メリットや利用手順を解説!」を参照。
ITプロパートナーズ
![]() はIT案件に特化したフリーランスエージェントです。
はIT案件に特化したフリーランスエージェントです。
週2〜3日から参画できる案件が豊富なので、起業したい人にもおすすめです。
いずみ週2〜3日の案件はある程度スキルがないと紹介してもらえない印象です。
とはいえ、週5の案件ももちろんありますし、僕が利用した時は迅速・丁寧に対応していただきました!
まとめ
今回は、ヤフオクの自動延長なし商品を抽出する方法について解説しました。
以下が本記事のまとめになります。

- おすすめ本

Pythonの勉強なら「独習Python![]() 」が体系的に学べるのでおすすめですよ♪
」が体系的に学べるのでおすすめですよ♪
いずみ最後までお読みいただき、ありがとうございました!
スクロールできます
| 【当サイト】おすすめフリーランスエージェント3選 | |||
|---|---|---|---|
| エージェント | 評価 | ポイント | 公式サイト |
レバテックフリーランス | 5.0 | 業界最大級のエージェント。 高単価案件が豊富。 | 公式 |
Midworks | 4.8 | 満足度調査で 3年連続3冠を達成。 | 公式 |
ITプロパートナーズ | 4.6 | 週2〜3向けの案件が豊富。 | 公式 |
- クソおすすめ本
 いずみ
いずみ海外のエンジニアがどういった思考で働いているかが理解できます。
海外に行く気はないけど海外エンジニアの動向が気になる雑魚エンジニアにおすすめです(本当におすすめな本しか紹介しないのでご安心を)。
